Se están detectando cientos de miles de intentos de ataque que buscan explotar la vulnerabilidad.
En muchos casos, la actualización de los sistemas de TI y la instalación de parches de seguridad es un asunto silencioso que a los líderes empresariales poco les preocupa, ya que están más atentos a conseguir que se apruebe un presupuesto para que el equipo de TI pueda llevar adelante esta tarea. Sin embargo, ese enfoque silencioso a veces se ve alterado cuando surge una noticia de último momento sobre una empresa que sufrió un ciberataque o una brecha de datos debido a una vulnerabilidad en algún software que estaban usando. La lectura de una historia de este tipo debería generar inmediatamente algunas preguntas a los líderes de cualquier empresa. Las más importantes son: “¿Mi empresa está usando ese software? Si es así, ¿hemos aplicado el parche?”
El caso de la vulnerabilidad Log4Shell debería generar estas y otras preguntas. A modo de contexto, Log4Shell es el nombre que se le dio a esta vulnerabilidad que involucra un fragmento de código —la librería Log4j 2 de Apache— que es utilizado en todo el mundo y perfectamente podría estar presente en algún software que usa su empresa, incluso sin que el personal de TI lo sepa explícitamente. Además, para los atacantes es bastante fácil de explotar y las consecuencias para las empresas podrían ser muy peligrosa.
Los ciberdelincuentes están escaneando Internet para enviar paquetes maliciosos con el objetivo de comprometer cualquier sistema expuesto a Internet que utilice una versión vulnerable de esta librería.
En este sentido, si su sistema procesa uno de esos paquetes maliciosos es posible que ya esté comprometido, porque el atacante ha hecho que uno de sus sistemas intente abrir un sitio web malicioso y descargue malware que podría incluso tomar control total del mismo. De la misma manera, un atacante que ya esté dentro de su red podría moverse fácilmente a otros sistemas utilizando el mismo enfoque de ataque.
Hasta ahora, los sistemas de detección de ESET han arrojado intentos de ataque que buscan distribuir malware, como mineros de criptomonedas, los troyanos Tsunami y Mirai, así como Meterpreter, la herramienta para realizar pruebas de penetración. Es probable que sea cuestión de tiempo antes de que los ataques se intensifiquen y los actores de amenazas avanzadas comiencen a intentar explotar esta vulnerabilidad de forma masiva. Ya se detectaron ataques de ransomware intentando explotarla.
El momento de auditar y actualizar es ahora
La vulnerabilidad Log4Shell ha provocado que empresas en todo el mundo estén realizando una auditoría completa de todo el software que utilizan y/o desarrollan para detectar la presencia de versiones vulnerables de la librería Log4j 2. Con cientos de miles de intentos de ataque recientemente detectados y bloqueados solo por los sistemas de ESET, no hay tiempo que perder en esta búsqueda.
Por lo tanto, los líderes de las organizaciones deben acercarse lo antes posible al equipo de TI y asegurarse de que se esté realizando una búsqueda completa de todos los activos de software de la A a la Z. Muchas empresas de desarrollo de software ya han auditado sus productos y han comunicado a los clientes si han sido afectados por Log4Shell y, de ser así, qué mitigaciones deberían implementar los clientes para minimizar los riesgos. Dicho esto, es importante que el equipo de TI de su organización busque esas comunicaciones de inmediato. El comunicado para los clientes de ESET está aquí.
Es muy importante que una vez que se identifiquen las versiones vulnerables de la librería Log4j el equipo de TI actualice la librería a la última versión, que actualmente es 2.16.0. Los administradores de TI pueden seguir los consejos de mitigación que se comparten aquí.
Hace unos días que el desarrollador de KDE Nate Graham escribió un artículo que dio bastante de de que hablar y que merece la pena recuperar, cuyo asunto podría resumirse en la idea que se recoge en el titular: ¿hacer el software de KDE más sencillo podría atraer a más usuarios? Este tipo de reflexiones nunca están de más y justo el caso que nos ocupa tiene su punto, porque como sabéis siempre se ha acusado a KDE de estar hinchado en cuanto a opciones y, por lo tanto, de resultar más complicado para el recién llegado.
Por el software de KDE nos referimos a todo, incluyendo el escritorio KDE Plasma, las aplicaciones que lo acompañan y el resto de componentes; y por Nate Graham nos referimos a la persona que nos mantiene puntualmente informados con su This week in KDE, además de contribuir en otros muchos temas técnicos con especial atención por lo general en la experiencia de usuario, uno de los vectores más delicados cuando hablamos de software libre. Sin embargo, en esta ocasión creo que ha errado el tiro, así que voy a dar mi opinión al respecto, aunque en ningún caso se trata de una réplica, sino de complementar al reflexión y a lo sumo abrir debate.
Primero, la suya, que desarrolla en este artículo y este otro, surgido el último de los comentarios suscitados por el primero. Resumiendo la historia, cuenta Graham que el porcentaje de usuarios avanzados capaces de utilizar lo que denomina como aplicaciones complicadas, es muy ajustado y KDE como proyecto no puede dar la espalda a lo que es una base de usuarios mayoritaria. Pero comencemos por el principio.
¿Cómo determina Graham qué son usuarios son avanzados y básicos? Lo hace base a una curiosa tabla con cinco niveles que a pesar de lo singular, tiene su sentido; pero también con una encuesta de la Organización para la Cooperación y el Desarrollo Económicos que viene a decir que «casi el 40% de los adultos en los países ricos prácticamente no tienen habilidades informáticas«… no digamos ya en los países en desarrollo o los pobres, añado yo.
Así, Graham entiende que «KDE nunca logrará dominar el mundo con un software que solo puede ser utilizado por un máximo del 30% del mercado. Para ampliar su atractivo, necesitamos que nuestro software sea utilizable por al menos las personas en el siguiente nivel […], lo que duplica el potencial al 60% del mercado, pasando de una minoría a una mayoría sólida».
KDE Plasma 5.23
«¡Pero, espera! ¿No supondrá esto hacer el software de KDE «tonto»? ¿No alienaremos a nuestra audiencia actual de usuarios […]?», añade. «Después de todo, el software para teléfonos inteligentes optimizado para usuarios básicos es realmente simple y limitante. O sea, es un riesgo». Y a partir de este punto sigue desarrollando su reflexión, en mi opinión, sin demasiado tino, aunque de todo hay.
Por ejemplo, señala Graham algo que ha sido una constante en el mismo desarrollo del software de KDE, se haya conseguido en mayor o menor medida: lo del lema ese de simple por defecto, potente cuando se necesita, lo cual viene de largo, no es nada nuevo. Y ahí podemos estar de acuerdo: mientras no quitéis opciones, simplificad las interfaces por defecto tanto como se pueda, no hay problema en eso.
Ahora bien, Graham le sigue dando vueltas al asunto y al supuesto precio a pagar por simplificar el software, poniendo finalmente un límite: «podemos excluir deliberadamente a las personas sin conocimientos de nuestro público objetivo, ya que probablemente nunca estarán contentas con el software de KDE. Nuestro enfoque en la potencia se desvanecerá incluso en las aplicaciones más simples y nunca será atractivo para ellos. GNOME y elementary OS pueden tener esos usuarios».
Ahí es cuando me explota la cabeza… por una razón muy sencilla: ¿si GNOME y elementary OS pueden tener esos usuarios… por qué no los tienen ya? Muy sencillo: porque…
El problema del escritorio Linux no es el «software»
Sobre esto hemos discutido mil veces en estas páginas y discutiremos otras tantas, porque es un tema tan candente como recurrente. Pero así es como se rebate hasta el último punto y disposiciones que plantea Graham: todos los usuarios que se ganan para KDE o para el escritorio Linux en general, no van a depender de si las aplicaciones son más o menos complejas o tienen más o menos opciones. Nunca ha sido así y nunca lo será.
Comparémoslo con el software de éxito, Windows o Android. ¿Son más complicadas las aplicaciones de KDE que las de Windows? ¿En serio? ¿Es más complicado usar y configurar Dolphin que el explorador de Windows? ¿Son más confusas las preferencias de KDE Plasma que las de Windows? Habrá ejemplos puntuales a favor de uno u otro, pero… Y lo mismo pasa en el móvil: puede que haya aplicaciones muy básicas, pero también las hay complejas, repletas de opciones… ¿Y qué hay de las preferencias?
Sinceramente, dudo mucho que el usuario básico al que superan las preferencias de KDE se va superado también por las preferencias de Windows o de Android, y lo mismo vale para cualquier aplicación que caiga en sus manos. Vamos, que no creo que tenga nada que ver el atraer usuarios con si las interfaces de tu software son más o menos sencillas y el mismo Graham se pone delante: ¿dónde están los cientos de millones de usuarios de GNOME y elementaryOS?
Está bien esforzarse en mejorar y el margen de mejora de las aplicaciones de KDE en materia de diseño y usabilidad es amplio, como lo es en prácticamente todo el software que hay por ahí. Pero pensar que ese es el motivo por el que los usuarios no usan KDE o, para el caso, el escritorio Linux… O, dicho de otra forma: pensar que mejorando eso no solo se va a atraer a más usuarios, sino que se puede abrir la puerta a la aspiración a semejantes porcentajes, cuando ese no es un problema para nada grave…
Repasamos qué es el Machine Learning, cómo funciona el proceso, tipos de aprendizaje automático y cómo se utiliza en ciberseguridad.
Si bien hemos hablado en varias oportunidades sobre Machine Learning e incluso de nuestro producto Augur, en esta ocasión haremos un pequeño repaso teórico para aquellos que no están tan familiarizados con esta tecnología.
¿Qué es Machine Learning?
El aprendizaje automático, en inglés Machine Learning (ML), es una rama de la ciencia que permite a las computadoras a través de un conjunto de técnicas realizar tareas sin ser programadas explícitamente. A través del ML los ordenadores pueden generalizar su comportamiento a partir de datos procesados con el objetivo de realizar predicciones sobre datos futuros.
A modo de contexto, el término Machine Learning existe desde hace varias décadas, cuando Arthur Samuel lo utilizó por primera vez en los laboratorios de IBM en el año 1959 y lo definió como:
“Campo de estudio que le da a las computadoras la capacidad de aprender sin ser programadas explícitamente”
Sin embargo, fue recién en la década de 1980 cuando este concepto tomó más fuerza con la aparición de las redes neuronales artificiales (ANN – Artificial Neural Network) y luego después de otra década se empezó a utilizar por diversos especialistas con el objetivo de resolver algunas problemáticas de la vida diaria.
Similar a lo que ocurrió a principios del 2010 con las tecnologías Cloud cuando muchos consideraban que no iban a tomar fuerza, lo mismo pasó con el ML. Hoy en día esta ciencia es utilizada por diversas empresas: Facebook, Netflix, YouTube, Google o Amazon, por nombrar algunas.
Los sistemas que utilizan Machine Learning más populares son el reconocimiento de voz y el reconocimiento facial, perfilamiento de clientes en marketing, estudios de mercado, y a esto último se le está sumando automatización para IoT, automóviles autónomos, y hasta incluso los famosos robots de ayuda.
Ahora bien, la pregunta central es: ¿qué tipo de necesidades podría satisfacer el Machine Learning en la industria de la ciberseguridad? Para responder esto antes debemos dar un pequeño marco teórico para comprender dónde podríamos aplicar Machine Learning en la ciberseguridad.
¿Cómo se clasifica el ML en general?
A grandes rasgos, lo podemos clasificar como:
Si bien, tal como se observa en la figura anterior, existen varios algoritmos de Machine Learning, en este artículo abordaremos dos para entender cómo podrían ser utilizados en el área de la ciberseguridad:
Aprendizaje supervisado: está enfocado en determinar las probabilidades de nuevos eventos en función de eventos observados anteriormente. Dentro de este algoritmo encontramos otras dos categorías:
Clasificación: los algoritmos de clasificación predicen a qué categoría pertenece una entrada en función de las probabilidades aprendidas de las entradas observadas previamente. Por ejemplo: determinar si un archivo es malware o no.
Regresión: los modelos de regresión (lineal, logística) predicen un valor de salida para una entrada determinada en función de los valores de salida asociados a las entradas anteriores. Por ejemplo: predecir cuántas muestras de malware se detectarán al próximo mes.
Aprendizaje no supervisado: intentan encontrar patrones no etiquetados. Por ejemplo: determinar cuántas familias de malware existen en el conjunto de datos y qué archivos pertenecen a cada familia. Dentro de este tipo de ML se encuentra el “Clustering”, que consiste en agrupar un conjunto de objetos (cluster) por sus similitudes. Ejemplo: detección de anomalías, o familias de malware.
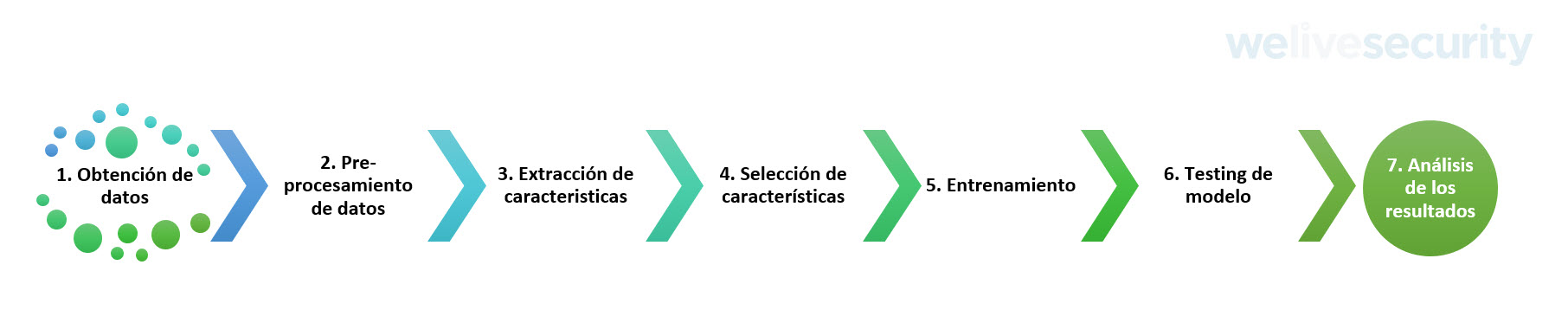
Etapas del Machine Learning
Aunque no seas experto en este tipo de tecnologías, es importante entender a rasgos generales cómo funciona el proceso general del ML, el cual se divide en las siguientes etapas:
Obtención de datos: Cualquiera sea el algoritmo de ML a utilizar, se debe poseer un gran número de datos para entrenar a nuestro modelo. Mayoritariamente los datos provienen de diversas fuentes.
Preprocesamiento: muchas veces los datos recolectados son categóricos, por lo que es necesario realizar un preprocesamiento y transformar esos datos en numéricos, ya que los algoritmos de ML trabajan solo con datos numéricos.
Extracción de características: se identifican los elementos que deben extraerse y someterse a análisis.
Selección de características: se identifican los atributos necesarios para entrenar el modelo de ML.
Entrenamiento: se entrena el modelo en base al algoritmo seleccionado de ML. En esta etapa se utiliza una parte de los datos para entrenar el modelo y otra parte para realizar la evaluación del mismo.
Testing: es considerado por muchos expertos la etapa más importante, ya que, teniendo el modelo entrenado, se debe validar el modelo. Para esto, los datos que se separaron en la etapa anterior, datos de validación, son utilizados para ejecutar el modelo de ML y evaluar si el modelo ofrece los resultados esperados.
Análisis de resultados: en esta etapa se buscan los errores a corregir y ajustar el modelo.
Ya explicado los tipos de ML que existen y sus etapas, procederemos a detallar las áreas en donde se podría utilizar esta tecnología dentro de la ciberseguridad.
Áreas de la ciberseguridad en las que se está aplicando el Machine Learning
En general, los productos de aprendizaje automático se crean para predecir ataques antes de que ocurran, pero dada la naturaleza sofisticada de estos ataques, las medidas preventivas a menudo fallan. En tales casos, el aprendizaje automático ayuda a remediar de otras maneras cómo reconocer el ataque en sus etapas iniciales y evitar que se propague por toda la organización. En la siguiente figura se identifica las necesidades que podría cubrir el ML dentro del campo de la ciberseguridad:
El lado B del Machine Learning
Por ahora solo se hablo de cómo el Machine Learning podría llegar a ser un aliado para el campo de la ciberseguridad, pero no nos debemos olvidar que el ML en la actualidad es utilizado para diversas áreas. Por ejemplo: reconocimiento facial, en el campo de la genética, compresión de textos, vehículos autónomos y robots, análisis de imágenes, detección de fraudes, predecir tráfico, selección de clientes, posicionamiento en buscadores, reconocimiento de voz, entre otros aplicativos. Sin embargo, todos estos tipos de aplicativos funcionan a partir del procesamiento de enormes cantidades de datos.
La pregunta entonces es: ¿Puede ser un modelo de Machine Learning vulnerado por cibercriminales? La respuesta es: Sí.
Así como se estudia dentro de la ciberseguridad modelos de prevención para distintas tecnologías, actualmente se está empezando a poner foco en la aplicación del ML a estos modelos. Por eso dentro del campo de la ciberseguridad está tomando más relevancia el concepto de Adversarial Machine Learning.
¿Qué es Adversarial Machine Learning?
El término “adversario” se utiliza en el campo de la ciberseguridad para describir al procedimiento mediante el cual se intenta penetrar o corromper una red.
En este caso, los adversarios pueden usar una variedad de métodos de ataque para interrumpir un modelo de aprendizaje automático, ya sea durante la fase de entrenamiento (llamado ataque de “poisoning” o envenenamiento) o después de que el clasificador haya sido entrenado (un ataque de “evasión”).
Conclusiones
En los últimos años el termino de Machine Learning ha tomado más importancia para los sistemas, claro está que es un tipo de tecnología en crecimiento y que tiene muchísimos beneficios para diversos sectores. En cuanto al área de la ciberseguridad, se puede utilizar ML en Threat Intelligence; por ejemplo, en la detección de amenazas, ya que esta área produce un gran volumen de datos en su inicio.
Además, se está buscando incluirlo dentro de las áreas de Threat Hunting y para la clasificación certera de familias de malware.
Sin dudas esta tecnología es un gran aliado para múltiples sectores, pero existe la posibilidad de que estos modelos de inteligencia de datos sean modificados y que esto afecte gravemente el negocio que los está utilizando. En un próximo artículo profundizaremos en lo que respecta la temática de Adversarial Machine Learning.
Pop!_OS 21.10 es la nueva versión de la distribución de System76, el más conocido ensamblador de equipos con Linux y con poco que hayas seguido su desarrollo, ya sabes a lo que atener: derivada de Ubuntu con GNOME cada vez más personalizado que, no obstante, tiene fecha de caducidad… Pero comencemos por el principio.
Y el principio de Pop!_OS 21.10 no es otro que su propio lanzamiento, cuyo número de versión no engaña y viene a decir que estamos ante una de las derivadas de Ubuntu 21.10, pero con matices, pues System76 aplica personalizaciones que van de dentro afuera, incluyendo kernel, controladores gráficos y entorno de escritorio y aplicaciones.
Así, Pop!_OS 21.10 llega con una versión del kernel más reciente que la de Ubuntu; en concreto, la última versión que ha visto la luz, actualizaciones incluidas: Linux 5.15.5. Lo mismo para con los controladores gráficos de NVIDIA (los de AMD e Intel van integrados en el propio kernel y Mesa).
Pop!_OS 21.10 trae también novedades en el instalador de sistema, o mejor dicho, en el sistema de recuperación del sistema, valgan las redundancias, el cual permite reinstalar sin eliminar los archivos y que a partir de ahora rfeconoce si Pop!_OS está instalado, ofreciendo la opción de ejecutar una actualización antes de desbloquear una unidad de almacenamiento cifrada.
Sin embargo, la gran novedad de Pop!_OS 21.10 es lo que han llamado como Application Library o biblioteca de aplicaciones, un nuevo lanzador de aplicaciones que reemplaza al propio de GNOME y que aparece en una ventana en el centro de la pantalla. Por lo demás es igual al lanzador tradicional, se puede abrir de igual modo… pero aporta según System76 una serie de ventajas:
Mejor experiencia multimonitor, al aparecer el lanzador siempre en en la pantalla que tiene el foco del cursor.
Lista de aplicaciones en orden alfabético que facilita el localizar una aplicación en concreto cuando se tienen muchas instaladas.
Organización de aplicaciones simplificada, pudiendo crear carpetas que actúan como pestañas personalizas con arrastrar y soltar.
Búsqueda más accesible que filtra entre aplicaciones instaladas y disponibles en la tienda de Pop!_OS.
Y «el tamaño correcto: logra la misma densidad de información mientras usa mucho menos espacio. La biblioteca de aplicaciones proporciona la experiencia óptima, especialmente en monitores ultra anchos.»
¿Cómo se ve y cómo funciona el nuevo lanzador de aplicaciones de Pop!_OS? Mira el siguiente vídeo:
Otras novedades de Pop!_OS 21.10 incluyen un repositorio propio ampliado en el que alojar más aplicaciones para garantizar que se está ofreciendo la versión más reciente de las mismas; mejoras en el proceso de garantía de calidad de las nuevas versiones del sistema, lo cual incluye las actualizaciones que recibe cada versión en curso; y algunas actualizaciones de GNOME retocadas para la ocasión.
Con todo, desde System76 recomiendan hacer copias de seguridad antes de actualizar desde la versión anterior del sistema, por si acaso. En el anuncio de lanzamiento enlazado más arriba se dan instrucciones específicas paso a paso.
Pero este lanzamiento trae más novedades si cabe: Pop!_Pi Tech-Preview for Raspberry 4, al que poco más cabe añadir. En efecto, habemus versión de Pop!_OS para Raspberry Pi, aunque como advierte su denominación, se trata por el momento de una imagen de instalación solo para pruebas. En ambos casos, tanto la descarga de Pop!_Pi Tech-Preview for Raspberry 4 como la de Pop!_OS 21.10 se encuentra disponibles en la página oficial del proyecto.
Y eso es todo, aunque habrá mucho más: desde que System76 anunció Cosmic como nuevo entorno de escritorio de Pop!_OS no han dejado de avanzar en ese camino y por más modificaciones que le hagan a GNOME, la bifurcación figurada está tomada y los planes de desarrollar un escritorio propio en Rust son un hecho.
Además, la relación entre System76 y GNOME no es mala, es pésima, y todo cuenta… aunque desprenderse por completo del software de GNOME es misión imposible a estas alturas del partido. Claro que ya han dicho que no lo harán.
Signal es tal vez la aplicación de mensajería que más privacidad ofrece a sus usuarios, pero un factor que frena su crecimiento posiblemente sea la baja cantidad de usuarios en comparación con WhatsApp o Telegram.
Durante mayo de 2021, y luego de que WhatsApp anunciara una renovación en su política de privacidad y términos de uso, otras aplicaciones de mensajería instantánea comenzaron a ganar popularidad. Entre las más descargadas después de WhatsApp encontramos a Telegram y Signal.
Ya te contamos en un post anterior las opciones que ofrece Telegram para configurar la privacidad y seguridad de los usuarios y también sobre las diferencias entre WhatsApp, Telegram y Signal. En esta ocasión, profundizaremos en Signal, la aplicación menos conocida (y más anónima) de las mencionadas.
Principales características de Signal
Signal, antes llamada TextSecure, es una aplicación de mensajería de texto y voz que desde sus inicios estuvo caracterizada por la privacidad y seguridad. Es de código abierto, es decir, su código es accesible y auditable por cualquier usuario y, además, es mantenida por una organización sin fines de lucro que opera en base a donaciones.
En cuanto a la recopilación de datos, Signal solamente requiere del número de teléfono móvil del usuario. Si bien cuenta con funcionalidades como la sincronización de los contactos o la posibilidad de contar con una foto de perfil, obtiene los datos utilizando algoritmos que utilizan cifrado y no requieren de un almacenamiento extra en los servidores de la aplicación.
Además, todas las comunicaciones realizadas en la aplicación están cifradas por defecto y de manera obligatoria. De hecho, la organización detrás de Signal creó su propio protocolo de cifrado para ello, que combina complejos algoritmos criptográficos para asegurar que sea imposible quebrantarlo.
Finalmente, la aplicación solicita permisos similares a WhatsApp y Telegram. Sin embargo, estos corresponden a funcionalidades adicionales (como importar contactos, enviar fotografías o enviar y recibir mensajes de texto mediante Signal), y se pueden desactivar sin afectar al funcionamiento esencial de la aplicación.
Configuraciones de privacidad en Signal
Como en la mayoría de las aplicaciones de mensajería, encontramos las configuraciones relacionadas a la seguridad y privacidad en el menú Ajustes. En Signal, podemos encontrarlos presionando los tres puntos en la esquina superior derecha.
Además de configuraciones de perfil, ver dispositivos en donde hayamos iniciado sesión y demás ajustes de apariencia y almacenamiento, encontramos las opciones de privacidad bajo la categoría Privacidad.
Dentro de esta opción podemos encontrar la lista de usuarios bloqueados, así como opciones aplicadas a las conversaciones, que van desde la posibilidad de inhabilitar las notificaciones de lectura o tecleo, hasta seleccionar un tiempo de desaparición de los mensajes. Este último funciona como la autodestrucción de mensajes en Telegram, pero configurado para cualquier chat que iniciemos. Es decir, después de que el mensaje sea visto, se eliminará de los dispositivos del emisor y receptor en el tiempo que seleccionemos. Esta configuración también puede ser aplicada dentro de un chat en específico, en los ajustes dentro del mismo.
Además, se listan opciones de seguridad, como el forzar el bloqueo del dispositivo luego de un tiempo configurable, que puede no coincidir con el tiempo de bloqueo que tiene nuestro teléfono para cualquier ocasión.
Otra de las características interesantes que presenta Signal es la posibilidad de bloquear las capturas de pantalla, tanto por aplicaciones externas como por el mismo uso de capturas de pantalla tradicionales estando dentro de la aplicación. Sin embargo, es importante notar que existen formas, un tanto más complicadas, de obtener esta información. Por ejemplo, fotografiar la pantalla con otros dispositivos.
Finalmente, la opción de Teclado en modo incógnito le posibilita a Signal solicitarle a nuestro teclado que desactive el aprendizaje automático de palabras o frases, aunque esto no es garantía de que nuestros mensajes sean analizados por nuestro teclado.
También tenemos disponibles las opciones más avanzadas, para quienes quieran asegurar un poco más la aplicación.
En primer lugar, la opción de eliminar nuestro número de los servidores de Signal desactivando las llamadas y mensajes que utilicen los servicios de esta. Si desactivamos la opción solo podremos enviar y recibir mensajes de texto a través de la aplicación. Además, podemos obligar a pasar todas las llamadas que realicemos y recibamos a través de un servidor de Signal, evitando exponer nuestra dirección IP.
Finalmente, encontramos la opción del remitente confidencial. Según explican los propios desarrolladores en su blog, esto añade una capa extra de seguridad: No solo se cifra el contenido de los mensajes que enviemos, sino también quien los envía. Para esto, además de sus algoritmos de cifrado, utilizan verificaciones de un solo uso contra sus servidores para evitar casos de spoofing.
Conclusión
Signal se presenta como una alternativa versátil con configuraciones extra en lo que respecta a seguridad que sus contrapartes como Telegram y WhatsApp. El cifrado por defecto, la autodestrucción para todo chat y la opción de remitente confidencial son algunas de las opciones que aumentan nuestra privacidad dentro de Signal. Sin embargo, la abismal diferencia en cuanto a cantidad de usuarios hace que se dificulte utilizarla para contactarnos con nuestros conocidos.
Como toda aplicación, es importante tener en cuenta nuestras necesidades y expectativas de privacidad, y compararlas con las políticas de privacidad y términos y condiciones de Signal para asegurarnos que la aplicación sea adecuada para nuestro uso.
Ledger, la empresa creadora de hardware wallets, anunció este jueves el lanzamiento de una tarjera de débito para bitcoin y criptomonedas, llamada Crypto Life.
De acuerdo con la publicación oficial, el instrumento, que usará la red Visa, es resultado de una asociación entre Ledger y la compañía de servicios financieros Baanx Group. Con la tarjeta, los usuarios podrán pagar en más de 50 millones de minoristas y tiendas online.
También te podría interes
Según destacaron, el lanzamiento de la tarjeta tiene la intención de “satisfacer la creciente demanda” y “mover la aguja de las criptomonedas” como un medio de intercambio, en lugar de una reserva de valor. De esta manera, la compañía francesa que recientemente recaudó 380 millones de dólares comienza a expandir su suite de servicios más allá de los monederos físicos.
Las tarjetas podrán ser manejadas y cargadas desde la aplicación Ledger Live, disponible tanto en versión de escritorio como en móvil. Además, las tarjetas podrán abrir una línea de crédito para la obtención de efectivo, el cual se podrá gastar usando el instrumento financiero y teniendo a las criptomonedas como garantía. Lo interesante es que las tarifas y demás tasas parten de un 0%, aunque pueden variar, según la localidad.
De igual manera, la tarjeta facilitará la conversión de criptomonedas a monedas nacionales al momento de realizar un pago. También, podrás recibir tu salario directamente en la tarjeta y configurar un porcentaje para canjearlo de manera automática a bitcoins, ethers, stablecoins, entre otras monedas.
De momento, la tarjeta podrá ser utilizada por clientes en Reino Unido, Francia y Alemania, a partir del primer trimestre del año entrante. Para los clientes de los Estados Unidos, será a partir del segundo trimestre.
Sobre las criptomonedas con las cuales trabajará Crypto Life, están bitcoin, ether (ETH), tether (USDT), eurocash (EURT), USD Coin (USDC), Ripple (XRP), Baanx (BXX), Bitcoin Cash (BCH) y Litecoin (LTC).
De acuerdo con el directivo de Ledger, Ian Rogers, la tarjeta Crypto Life es un paso “hacia el reemplazo de las cuentas bancarias tradicionales”. Añadió, en declaraciones a Coindesk, que el nuevo instrumento responde a que los usuarios “cada vez más quieren hacer más y más con criptomonedas”.
Recientemente, CriptoNoticias reportó que Ledger añadió la opción para enviar y recibir transacciones en direcciones Taproot, la actualización más reciente del protocolo Bitcoin, brindando nuevas capacidades a sus usuarios.
A finales de este 2021, según fuentes del Gobierno, se activará en tu móvil la Carpeta Ciudadana, una suerte de cartilla digital desde la que podrás comprobar y gestionar los trámites que tienes con la Administración de forma rápida y remota.
Diseñar los servicios públicos digitales pensando en la ciudadanía: una tarea pendiente que por fin despega en España.
Reconócelo: no hay nada más tedioso que tener que llevar a cabo un trámite con la Administración pública, especialmente si para lograr esa odisea -porque en muchas ocasiones lo es- necesitas pegarte toda una mañana de tu vida sepultado en papeles. Y así nos viene a la cabeza esa mítica escena de Astérix y Obélix en la que recorren un laberíntico edificio de ventanilla en ventanilla y de formulario en formulario -si no la recuerdas.
Con un tercio de funcionarios trabajando en remoto, Madrid gestionó en 2020 un 61% más de expedientes electrónicos
Afortunadamente, algo hemos cambiado. Y mejorado. Gracias -o por culpa- de los nuevos tiempos pandémicos, algunas de las relaciones con la Administración se han agilizado y ahora, por ejemplo, en casi todas las gestiones puedes pedir una cita previa, lo que ayuda bastante a no tener que perder toda una jornada esperando a que te atiendan. También se ha avanzado a la hora de cumplimentar ciertos trámites, que se han digitalizado y te permiten hacerlo cómodamente desde el ordenador y sin tener que desplazarte.
Esa transformación tecnológica es a la que deben ir y a la que están yendo los servicios públicos, y si bien a nuestro Gobierno se le llena la boca hablando de la “robustez” de la Administración digital española, como la califica la secretaria de Estado de Digitalización e Inteligencia Artificial, Carme Artigas, todavía nos queda camino por recorrer: incluso ella misma admite que es necesario “mejorar la experiencia de usuario”.
«Queremos convertir la Comunidad de Madrid en una administración 100% digital»
Pero hay luz al final del túnel: a finales de septiembre, Artigas informó de primera mano que la Carpeta Ciudadana, el espacio que facilitará la relación de la población con las administraciones públicas, estaría disponible para su uso en teléfonos móviles en un plazo inferior a tres meses. Este anuncio nos pone hoy por hoy en la cuenta atrás para que tengamos en nuestro smartphone la que podría ser la clave para poner fin a largas y pesadas esperas para cumplir con una gestión burocrática.
¿Qué es la Carpeta Ciudadana?
La Carpeta Ciudadana es un desarrollo de la Administración que permite a las personas “de una forma ágil y sencilla, sin necesidad de registrarse y en un solo clic”, conocer los expedientes que tiene abiertos en los distintos organismos, sus asientos registrales entre administraciones o sus datos en poder de la Administración.
Para acceder a la Carpeta Ciudadana y operar en ella será suficiente con disponer de DNI electrónico o Certificado Digital en vigor, clave PIN o clave permanente. Será accesible a través de la sede electrónica del PAGe de la Administración General del Estado.
¿Para qué sirve la Carpeta Ciudadana?
La Administración Pública se digitaliza en tiempo récord a raíz de la crisis
La secretaria de Estado de Digitalización e Inteligencia Artificial subrayó algo importante cuando aseguró que antes de que acabase 2021 tendríamos en nuestro móvil la Carpeta Ciudadana: que la Administración pública tiene que guiarse por tres máximas en su relación con la ciudadanía, como son “no molestar ni estorbar, promover y catalizar los cambios e innovar”.
En este sentido, Artigas apuntaba que para cumplir la primera de esas metas están analizando los diez principales trámites que realizan empresas y ciudadanos con la Administración para volverlos lo más eficientes posibles.
Pero donde más hincapié hizo Artigas fue en la parte de catalizar todos esos cambios que se están produciendo. Así, defendió que “la Administración digital española es muy robusta”, como se demostró durante los meses más duros de la crisis sanitaria, en los que “al igual que no cayó Netflix, tampoco lo hizo la Administración”.
Diseñar los servicios públicos digitales pensando en la ciudadanía: una tarea pendiente que por fin despega en España
A lo que se refería la secretaria de Estado de Digitalización e Inteligencia Artificial es a que, en plena explosión pandémica, las cifras de la relación digital de la Administración con los ciudadanos alcanzaron niveles nunca vistos: se elevaron un 500% los trámites online, que pasaron de 5.000 a 90.000 de un día para otro, y se multiplicaron por diez los certificados digitales.
“Ha sido una explosión de la noche a la mañana y los sistemas han aguantado”, afirmaba Artigas, quien, sin embargo, admitía que el gran fallo de la Administración digital está en la experiencia de usuario, ya que son “sistemas antiguos que han envejecido mal”.
Con eso en mente, el objetivo de la Carpeta Ciudadana es, ‘sencillamente’, mejorar la relación con la Administración, de manera que sea una iniciativa con la que el Gobierno pueda “seguir avanzado en el proceso de digitalización del sector público español con un especial foco en mejorar la usabilidad de sus servicios”.
Ser más Amazon y menos ‘intranet’
«No somos Netflix, pero trabajamos para que relacionarse con la Administración sea una tarea sencilla y accesible»
Probablemente con lo que pongo en la línea de encima se entiende todo: la meta de Artigas y su equipo es equipararse a los tiempos y ser capaces de generar un producto ‘usable’, más parecido a la experiencia que tiene un usuario cuando entra en Amazon a comprar que a la que tiene cuando accede a la vieja intranet de su empresa para ver el tablón de noticias -plataformas, por cierto, que también están viviendo una importante mejora hoy en día-.
Si bien la secretaria de Estado de Digitalización e Inteligencia Artificial es consciente de que esos son portales “en lo que todo es más sencillo”, también reconoce que “en las plataformas diseñadas por la Administración no es tan fácil lograrlo [simplificar], ya que deben ser robustas y con unos condiciones de seguridad”.
Aragón apuesta por un modelo de gobernanza de datos
En este contexto, Artigas señalaba que el reto más urgente al que debe enfrentarse la Administración para mejorar su usabilidad y la de sus herramientas y aplicaciones es trasladar los servicios públicos al smartphone. De hecho, una de las metas del Gobierno es que para 2025 el 50% de los servicios estén disponibles en dispositivos móviles. Y es por eso que la secretaria de Estado está a punto de desvelar un nuevo avance que llegará directo a nuestros teléfonos. Estén atentos a sus pantallas.
Lo adelantábamos el sábado en MC, pero como es evidente, iba a tener su hueco aquí en MuyLinux. Hablamos del lanzamiento de la versión estable de Microsoft Edge para Linux, el ya no tan flamante navegador web de Microsoft, pero sí una de las apuestas que le está saliendo de la mejor manera posible a los de Redmond. Y mira tú por dónde, que tiene versión para Linux.
Ya lo sabíais, por supuesto, y es que desde que los rumores empezaron a circular hemos seguido de cerca este caso, de relevancia para el ecosistema de Linux por lo llamativo, más que por la necesidad, que lo cierto es que ni la había, ni hay. Pero como dijimos desde un principio, casi todo lo que llega a Linux es bienvenido y que haya una versión de Microsoft Edge para Linux no es una excepción.
De hecho, nos hicimos eco del salto de Microsoft hacia Chromium por lo que supuso, lamento de Mozilla incluido. Después ya vinieron los rumores, que no teníamos muy claros al principio, más tarde llegaron las confirmaciones, le siguieron las primeras versiones, todavía de carácter preliminar… No fue hasta este mismo año cuando Microsoft Edge para Linux implementó capacidades básicas del navegador como la sincronización de datos.
El momento reciente más importante se dio el pasado mayo con el lanzamiento de la versión beta de Microsoft Edge para Linux, lo cual presagiaba una llegada más pronta que tardía de la versión estable y a juzgar por las fechas, ha sido tardía, pero he aquí… más o menos. Más o menos, porque es inequívoco que la versión estable de Microsoft Edge para Linux ya está aquí y, sin embargo, no hay anuncio oficial de ningún tipo.
Era de esperar algún comentario, pero cuatro días después de que se haya descubierto el pastel no vamos a esperar más para darle su correspondiente entrada. En esencia, la página oficial de Microsoft Edge aún muestra el aviso de «No compatible con Linux» cuando entras desde Linux, por lo que la descarga reconocida sigue estando en el sitio de Microsoft Edge Insider, que es donde se pueden obtener directamente las versiones Beta y Dev.
No obstante, quien tenga instalado Microsoft Edge para Linux a través de los ejecutables oficiales ya sabrá que al igual que Chrome u otros navegadores, este te crea un repositorio propio desde el que actualizar la aplicación; un repositorio que se puede consultar cómodamente desde gestores tipo Synaptic, que también facilitan la instalación de las versiones de los canales en desarrollo del navegador.
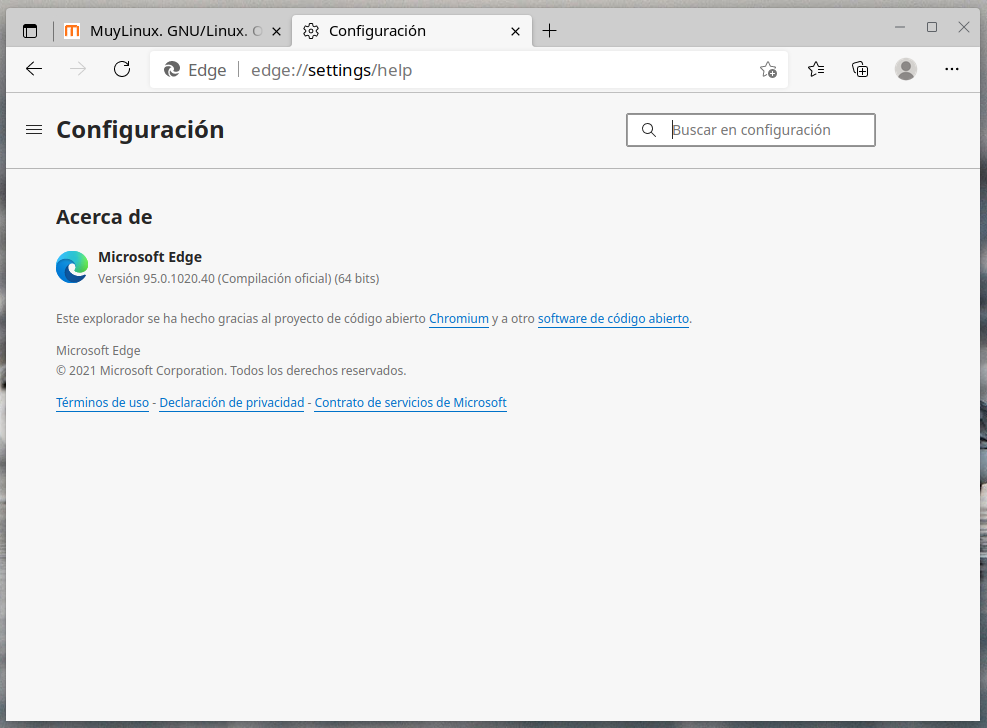
Así, no importa qué versión instalaste, porque el repositorio las incluye todas y puede variar cuando el paquete se actualiza… Y hace unos días que Microsoft Edge 95 se está desplegando entre las plataformas soportadas por el navegador. O sea que si tienes instalada la versión Beta o Dev de Microsoft Edge para Linux, puedes ir a los repositorios e instalar desde ahí la estable, que reconocerás a primera vista porque el icono es el corriente, sin etiquetas que adviertan de otra cosa.
Microsoft Edge estable para Linux
Si quieres instalar Microsoft Edga para Linux puedes hace eso, o puedes descargar directamente la versión estable, que aún no se muestra en la página oficial, pero sí en los repositorios oficiales, tal y como puedes comprobar en los enlaces (gracias a Deiki por el enlace de los paquetes RPM). Si tienes dudas de qué versión descargar, elige siempre la de fecha más reciente.
Descargar Microsoft Edge estable para Linux:
Paquete Deb
Paquete RPM
En efecto, el instalador oficial de Microsoft Edge para Linux solo está para distribuciones basadas en paquetería Deb, léase Debian o Ubuntu y derivadas, aunque la beta también lo está en RPM para Red Hat, SUSE y derivadas, por lo que habrá que esperar a que esté todo listo para todos. En otros sistemas se podrá reempaquetar, como sucede en Arch Linux, donde de hecho ya está disponible vía AUR. Y, ojo, porque parece que Microsoft prepara también versiones para ARM64.
Y pasamos ya a la reflexión de si hacía falta Microsoft Edge para Linux… y la respuesta es no, pero sí. Es decir, justo en el terreno de los navegadores web alternativas de calidad no faltan, por no señalar lo obvio: Microsoft Edge es software privativo. Además, el navegador presume de proteger la privacidad del usuario más que otros, pero no de Microsoft y según el estudio, es uno de los más dañinos en este aspecto, más incluso que Chrome, al punto de ser calificado como «una pesadilla para la privacidad».
Por otro lado, Microsoft está poniendo un gran empeño en hacer de Edge uno de los navegadores más completos y potentes del momento a nivel funcional y es junto a Vivaldi de los que más está innovando en este sentido: la personalización de su página de inicio, el soporte integrado para compras en línea, las colecciones y, por supuesto, la integración con Windows o Android vía el propio Edge, son algunas de sus características destacadas.
Ahora bien, ¿tendrá una buena acogida Microsoft Edge para Linux? Sabemos de sobra que nunca va a ser un navegador mayoritario, pero la pregunta no es esa, pues buena acogida la tuvo desde el minuto uno: ya en nuestra encuesta de fin de año pasado, Microsoft Edge quedó por encima de alternativas como Opera o Vivaldi, cuando aún ni contaba con una versión beta y si atendemos al descalabro que ha sufrido Chromium este año…
En mes y medio lanzaremos nuestra encuesta anual y comprobaremos cómo va el asunto. Mientras tanto ¿qué os parece Microsoft Edge para Linux?
¿Y qué dice GNOME de los planes de System76 de crear su propio escritorio? Nada. Lo dice de otra cosa, aunque no es exactamente GNOME como organización -aunque bien podría serlo- la que levanta la voz, sino Chris Davis, uno de sus de desarrolladores en un extenso artículo titulado «System76: un caso de estudio sobre cómo no colaborar con el upstream«.
«La siguiente publicación fue escrita en el contexto de los eventos que ocurrieron en septiembre. […] Esperé con la esperanza de que pudiéramos llegar a un final feliz con System76. A medida que pasa el tiempo, esa esperanza se ha desvanecido. Los intentos de conectar con System76 no han sido productivos, y creo que hemos dejado que la impresión que le han dado a la comunidad tecnológica sobre GNOME permanezca durante demasiado tiempo», comienza Davis.
Davis acusa a System76 de lanzar FUD (fear, uncertainty and doubt, tal cual) contra GNOME, pero también contra personas concretas del entorno de GNOME a raíz de los debates sobre el futuro del proyecto que dieron lugar al señalado artículo del GNOME Way. No es, además, la primera vez que System76 actúa así, según Davis, quien ha perdido su confianza en que la compañía corrija sus maneras.
Davis ilustra el «patrón de comportamiento de System76» con numerosos ejemplos que no vamos a reproducir porque este artículo se alargaría en exceso, pero que abarcan un poco de todo, dentro y fuera del entorno de GNOME: problemas de comunicación que derivan en ruptura, es el caso de LVFS; atribuciones ilegítimas y mal ánimo con la colaboración, es el caso de Ubuntu; y con GNOME, incluyendo posturas encontradas en materia de usabilidad y diseño.
Más allá de las posturas encontradas y la discusión, sin embargo, Davis acusa a System76 de emplear malas formas, tergiversar y atacar a GNOME como no cabría esperar de una compañía que se supone que comparte objetivos y vías de desarrollo y, añado yo, nada menos que con un miembro del Consejo Asesor de GNOME Foundation como es System76 desde 2018.
Cada uno de los ejemplos que ofrece Davis, no obstante, requiere de indagar y contemplar ambas partes en igual medida, así como darían para diferentes artículos. En el suyo están todas las fuentes y muestras de la actitud de System76 que no dejan una buena impresión. Ahora bien, dependiendo del ruido que genere esta queja en la comunidad, el ensamblador estadounidense contestará a buen seguro, como ha hecho de manera habitual.
Fuente: https://www.muylinux.com/
Cargando comentarios...
Deprecated: trim(): Passing null to parameter #1 ($string) of type string is deprecated in /home1/uiolibre/public_html/wp-content/plugins/simple-lightbox/includes/class.utilities.php on line 545
























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}