¿Te preocupa tu acceso a Telegram y tu privacidad? Esto es lo que deberías hacer en este momento.

En el momento en que redactamos este artículo, Pavel Durov, tras haber sido detenido en Francia, ha sido puesto en libertad bajo una fianza de 5 millones de euros y se le ha prohibido salir del país. No está nada claro cómo pueden desarrollarse los acontecimientos en el plano judicial, pero mientras tanto, los estafadores ya están explotando la atención masiva y el pánico que rodea a Telegram, y circulan muchos consejos dudosos en redes sociales sobre qué hacer con la aplicación ahora. Nuestra opinión es clara: los usuarios de Telegram deben mantener la calma y actuar únicamente en virtud de los hechos que se conocen hasta ahora. Si entramos en detalles, veamos qué podemos recomendar actualmente…
Privacidad de los chats y las “claves de Telegram”
En pocas palabras, la mayoría de los chats en Telegram no se pueden considerar confidenciales; y esto siempre ha sido así. Si has intercambiando información confidencial en Telegram sin utilizar chats secretos, debes asumir que se ha visto comprometida.
Muchos medios de comunicación apuntan a que la principal denuncia contra Durov y Telegram es su negativa a cooperar con las autoridades francesas y a facilitar las “claves de Telegram”. Supuestamente, Durov posee algún tipo de claves criptográficas que se pueden usar para leer los mensajes de los usuarios. En realidad, pocas personas saben realmente cómo se estructura el servidor de Telegram, pero a partir de la información disponible se sabe que la mayor parte de la correspondencia se almacena en servidores en forma mínimamente cifrada, es decir, las claves de descifrado se almacenan dentro de la misma infraestructura de Telegram. Los creadores afirman que los chats se almacenan en un país, mientras que las claves se almacenan en otro, pero si tenemos en cuenta que todos los servidores se comunican entre sí, no está claro hasta qué punto es efectiva esta medida de seguridad en la práctica. Resultaría útil si se confiscaran los servidores situados en un país, pero eso es todo. El cifrado de extremo a extremo, una función estándar en otros servicios de mensajería como WhatsApp, Signal e incluso Viber, se denomina “chat secreto” en Telegram. Está algo oculto en un lugar discreto de la interfaz y hay que activarlo manualmente para los chats personales seleccionados. Los chats de grupo, canales y la correspondencia personal estándar carecen de cifrado de extremo a extremo y se pueden leer, al menos en los servidores de Telegram. Además, tanto para los chats secretos como para los demás, Telegram utiliza su propio protocolo no estándar, MTProto, que contiene serias vulnerabilidades criptográficas, según se ha descubierto. Por lo tanto, los mensajes de Telegram teóricamente pueden ser leídos por:
- Administradores de los servidores de Telegram
- Piratas informáticos que logren acceder a los servidores de Telegram e instalen spyware
- Terceros con algún tipo de acceso otorgado por administradores de Telegram
- Terceros que hayan descubierto alguna vulnerabilidad criptográfica en los protocolos de Telegram y que puedan leer (selectivamente o en su totalidad) al menos los chats no secretos interceptando el tráfico de algunos usuarios
Eliminar los mensajes
Se ha recomendado a algunos tipos de usuarios que eliminen los chats antiguos en Telegram, como los relacionados con el trabajo. Este consejo parece cuestionable, ya que en las bases de datos (donde se almacenan los mensajes en el servidor), las entradas rara vez se eliminan; sino que simplemente se marcan como eliminados. Además, como en cualquier infraestructura informática importante, es probable que Telegram implemente un sistema robusto de copias de seguridad de los datos, lo que significa que los mensajes “eliminados” se mantendrán al menos en las copias de seguridad de la base de datos. Tal vez sea más eficaz para los dos participantes del chat (o para los administradores del grupo) eliminar por completo la conversación. Sin embargo, el problema de las copias de seguridad seguiría presente.
Copia de seguridad de los chats
Varios observadores han expresado su preocupación por que Telegram pueda ser eliminado de las tiendas de aplicaciones, que lo bloqueen o que se interrumpa su disponibilidad de algún otro modo. Si bien esto parece poco probable, hacer una copia de seguridad de los mensajes, las fotos y los documentos importantes sigue siendo una buena práctica de higiene digital.
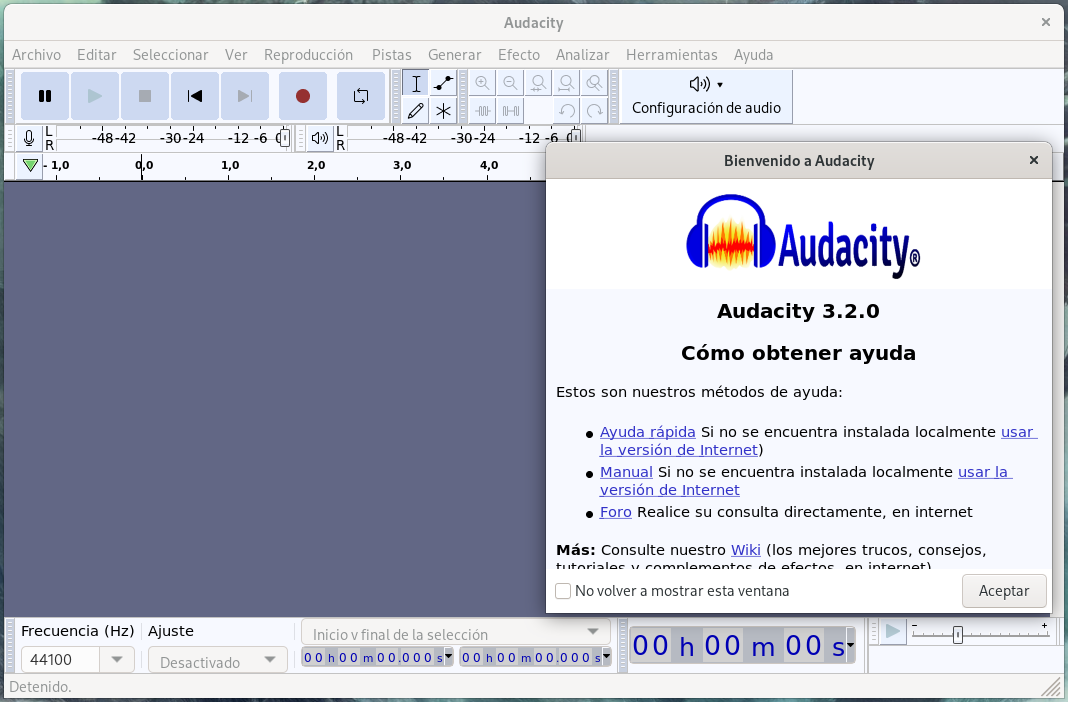
Para guardar una copia de seguridad de la correspondencia personal importante, tienes que instalar Telegram en el ordenador (aquí tienes el cliente oficial), iniciar sesión en tu cuenta y acceder a Configuración → Avanzado → Exportar datos de Telegram.
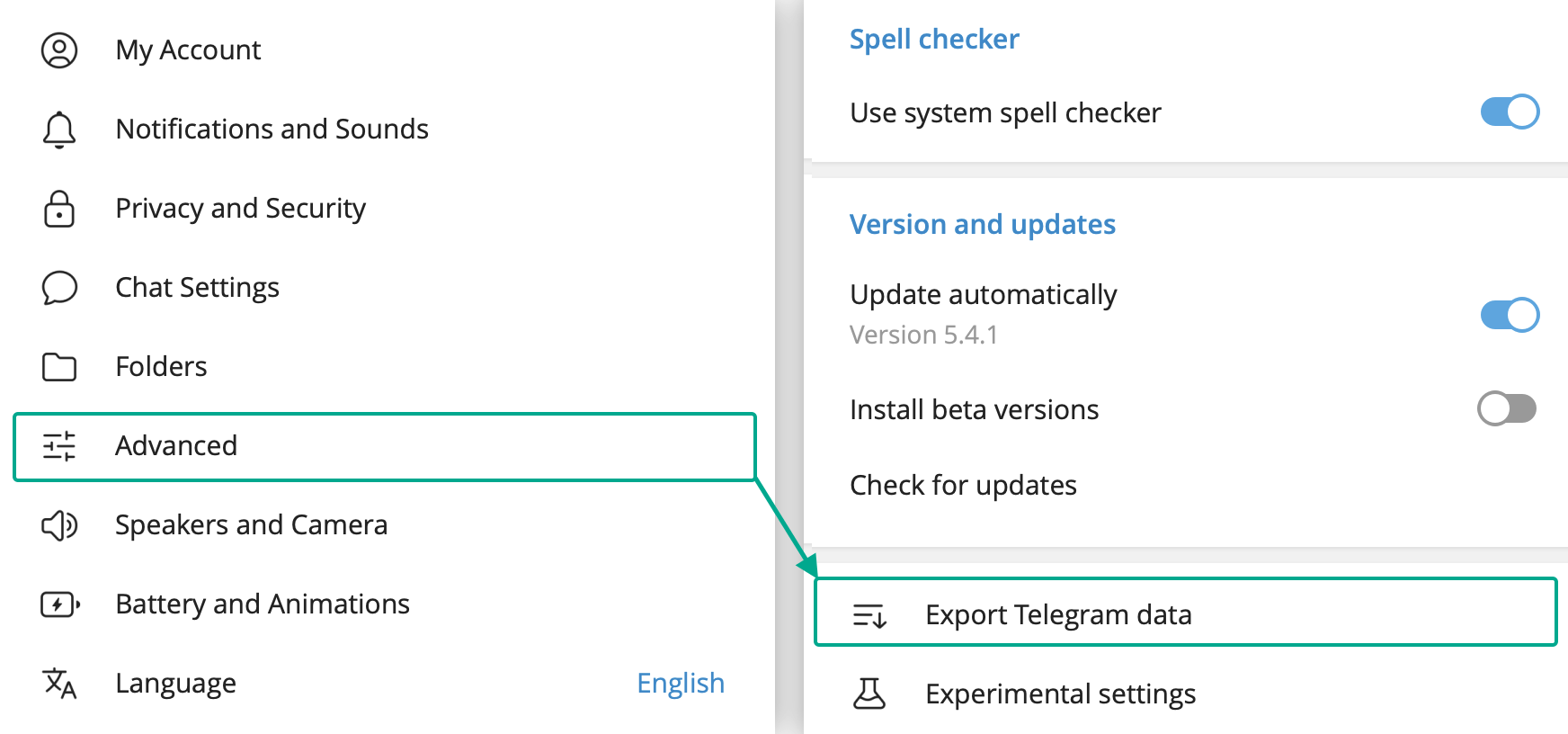
Cómo exportar todos los datos de Telegram
En la ventana emergente, puedes seleccionar los datos que quieres exportar (chats personales, chats de grupo, con o sin fotos y vídeos), establecer límites de tamaño de descarga y elegir el formato de los datos (HTML, para verlos en cualquier navegador, o JSON, para el procesamiento automático por parte de aplicaciones de terceros).
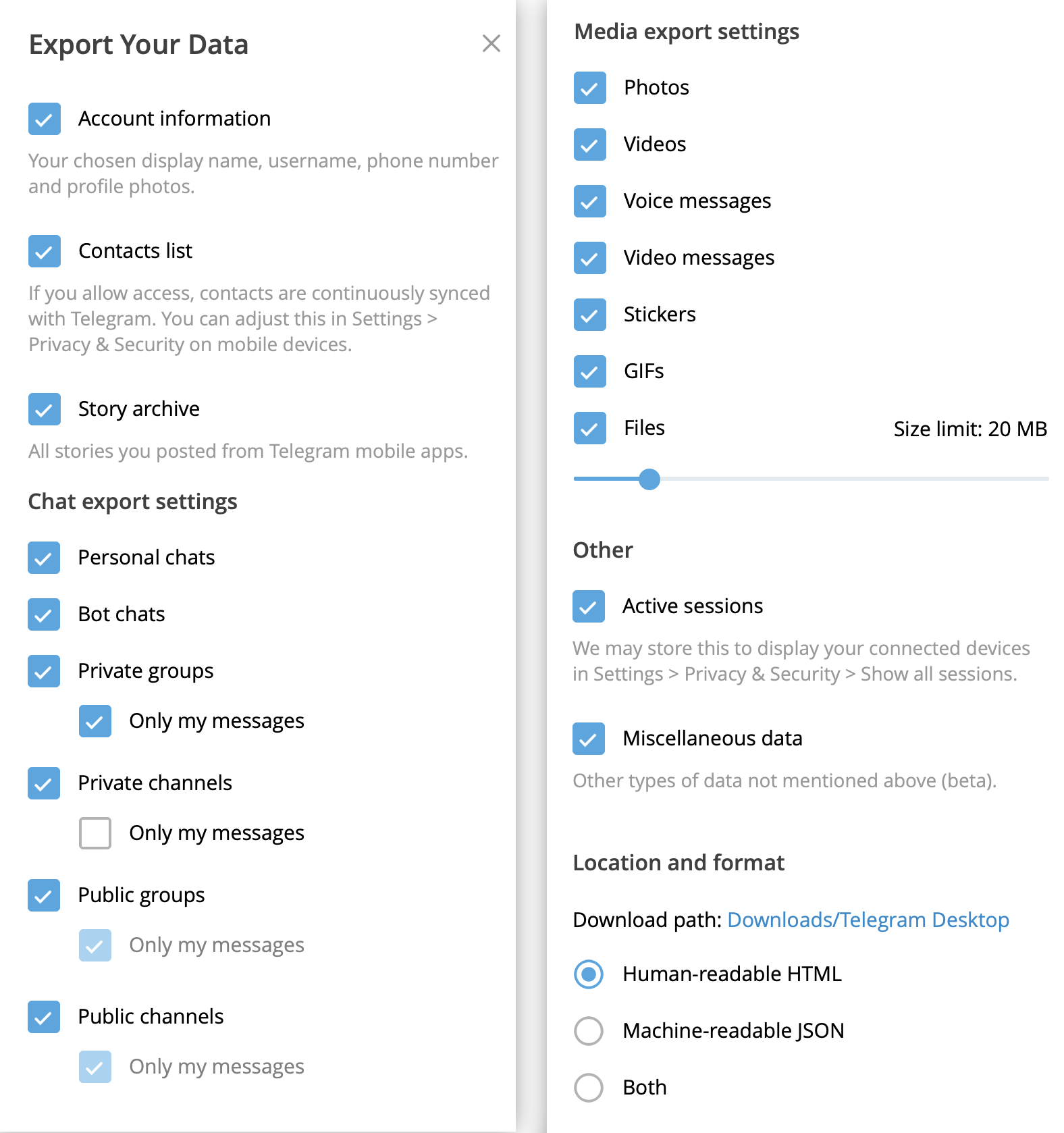
Ajustes para hacer una copia de seguridad de los datos de Telegram
Descargar los datos a tu ordenador podría llevar varias horas, así como requerir decenas o incluso cientos de gigabytes de espacio libre, en función de cuánto uses Telegram y de los ajustes de exportación seleccionados. Puedes cerrar la ventana de exportación, pero asegúrate de no salir de la aplicación y de no desconectar el equipo de Internet ni de la red eléctrica. Recomendamos usar únicamente la función de copia de seguridad del cliente oficial.
“Evitar la eliminación de Telegram” de los teléfonos
En primer lugar, echemos un vistazo a iOS. Los de Cupertino no eliminan aplicaciones de los teléfonos de los usuarios, ni siquiera cuando las aplicaciones se eliminan del App Store, por lo que cualquier consejo sobre cómo evitar la eliminación de Telegram de los iPhones será falso. Además, un método popular para “evitar la eliminación de Telegram” que circula en Internet ―usar el menú de Tiempo en pantalla― no impide que Apple elimine aplicaciones; solo evita que ciertos usuarios (por ejemplo, los niños) eliminen las aplicaciones ellos mismos: así pues, se trata de una función de control parental. Y eso no es todo: el arresto de Durov ha reavivado la vieja afirmación falsa sobre la eliminación remota de Telegram de los iPhones, que tanto Apple como Telegram negaron oficialmente en 2021.
En cuanto a Android, Google tampoco suele eliminar aplicaciones, salvo cuando se trata de software 100 % malicioso. Es cierto que los usuarios de otros ecosistemas (Samsung, Xiaomi, etc.) no cuentan con tales garantías, pero en Android resulta sencillo instalar Telegram directamente desde el sitio web de Telegram.
Clientes alternativos
Hay clientes no oficiales de Telegram que funcionan y son legales, e incluso un “cliente alternativo oficial”: Telegram X. Todos estos clientes usan la API de Telegram, pero no está claro si ofrecen alguna ventaja adicional o una mayor seguridad. Los cinco clientes alternativos principales disponibles en Google Play hablan de “seguridad mejorada”, pero solo se refieren a funciones como ocultar los chats en un dispositivo.
Como no, existe la posibilidad de que descargues malware que se haga pasar por un cliente alternativo de Telegram; los estafadores no pierden la ocasión de explotar la popularidad de la aplicación. Si te estás planteando usar un cliente alternativo, sigue estas recomendaciones de seguridad:
- Descárgalo solo desde las tiendas oficiales de aplicaciones.
- Asegúrate de que la aplicación lleve disponible un tiempo considerable y de que tenga una valoración alta y una gran cantidad de descargas.
- Utiliza una protección antivirus de confianza para todas las plataformas, como Kaspersky Premium.
Recaudación de fondos para Durov y en defensa de la libertad de expresión
Esto no está directamente relacionado con los chats de Telegram, pero es importante tener cuidado también con los estafadores que se hacen pasar por quienes recaudan fondos para la defensa legal de Pavel Durov (como si alguien como él necesitara dinero), pero que en realidad intentan robar datos de pago o donaciones en criptomonedas. Trata este tipo de solicitudes con gran sospecha y comprueba si la supuesta organización existe realmente y si está llevando a cabo dicha campaña.
Fuente: www.latam.kaspersky.com